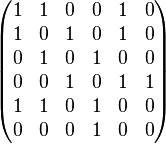Vi har startet en ny blog om matematik hvor vi skriver om matematiske emner, vi kommer i tanker om. Det er altså ikke med udgangspunkt i en TV-serie, men hvis vi falder over noget matematik i en tv-serie, så skriver vi sikkert også om det.
På bloggen for et par uger siden, skrev jeg om pseudotilfældige tal. Det er vigtigt at kunne frembringe tilfældige tal. Det må de amerikanske immigrationsmyndigheder sande. De har tilbagekaldt resultatet af årets lodtrækning om visa, fordi det ikke var tilfældigt nok. “The results were not valid because they did not represent a fair, random selection of entrants, as required by U.S. law. “ Man kan godt få visum udenom lodtrækningen, men der udloddes altså også nogle visa via lodtrækning.
Sidste Numb3rs-afsnit. Jeg sad og blev helt vemodig; især da jeg så ekstramateriale på DVD’en med skuespillernes afskedsfest…. Nå, men var der matematik? Ja! Noget i grafteoribranchen: Analyse af sociale netværk. Der var søgning i store datamængder og brug af Bayesianske filtre. (Se tidligere på bloggen.)
Netværk og “small world” Et netværk består af knuder og kanter, der forbinder knuderne. Mange strukturer kan repræsenteres som netværk: Det har vi haft noget om tidligere, men her kommer mere: De rent fysiske: Byer og flyforbindelser. Huse og elledninger. Byer og veje. Men også mindre oplagte: Personer og emails mellem dem – en kant mellem A og B viser, der er sendt mails mellem de to personer A og B. Og man kan sætte et tal (en vægt), der repræsenterer antallet af mails – måske to tal, som repræsenterer hhv. mails fra A til B og fra B til A. Hjernens neuroner interagerer med hinanden, og det kan beskrives som et netværk. Internettets servere og forbindelser mellem dem, eller WWW, hvor kanterne er links, giver to (forskellige) netværk. Hjernen, Internettet og andre store netværk er umiddelbart fuldstændig uoverskuelige. Men som vi alle ved, er det en meget begrænset del af nettet/www, vi faktisk bruger. Hjernen og Internettet er “Small World Networks”. At hjernen er det, kan man naturligvis ikke selv mærke, men det er der forskere, der har set på. Se Plus Magazine om komplekse systemer og om hjernen og twitterspace.
Filmen, fra Plus Magazine artiklen ovenfor, viser, hvordan hjernens netværk kan opdeles i mindre områder (delmængder af neuronerne), der allesammen har mange forbindelser til hinanden. Disse områder har så forbindelser til hinanden, men ikke så mange. OBS: Et område er ikke nødvendigvis et fysisk område. Man kan godt have forbindelse til moster Gerda i USA, men ikke til genboen. Skal man analysere et netværk, er det en fordel, hvis man kender den underliggende struktur. Er det et small world netværk, er forbindelserne opdelt i “indenrigs” (internt i de grupper, der har tætte forbindelser) og “udenrigs”. Eksempelvis har forskere fra Stanford undersøgt fMRI fra Alzheimerpatienter og set, at deres “udenrigskommunikation” er ok, mens der er problemer med nogle områders kommunikation internt. Så der groft sagt når information rundt hurtigt, men fra visse områder er det en forkert information.
Man kan bruge small world, når man opbygger netværk af computere (eller interne forbindelser i computeren.) Måske er det bedst at lave lokale tætte forbindelser – det kaldes kliker – og forbinde hver klike med andre kliker, men ikke hvert medlem af kliken med hvert medlem af andre kliker. Om det er en god ide, afhænger af, hvad netværket skal kunne.
Definition: Small world grafer er karakteriseret ved, at gennemsnitsafstanden mellem to knuder (antallet af kanter man skal gå ad for at komme fra en knude til en anden) vokser som Log(N), hvor N er antallet af knuder. Og at “clustering koefficienten” er høj. -Det er ikke en præcis definition, men der er, så vidt jeg kan finde ud af, ikke en, man alle er enige om…. En anden tilgang er at analysere, hvor mange kanter, der er i hvert hjørne. Og se på antallet af hjørner med en kant, antallet med to etc. Det regner man om til sandsynligheden for, at et tilfældigt hjørne har et givet antal kanter. (Man dividerer simpelthen antallet af hjørner, der har 7 kanter med det totale antal hjørner. det er sandsynligheden for at finde et hjørne med 7 kanter. ) Man får en sandsynlighedsfordeling. Fordelingen af antallet af hjørner er en egenskab ved grafer. Small world grafers kantfordeling ligner et polynomium. Den har tyk hale – der er stor sandsynlighed for mange kanter. D.J.Watts og S.Strogatz skrev en artikel i Nature i 1998, Collective dynamics of ‘small-world’ networks, hvor de navngav fænomenet. Watts skrev den populære bog “Six degrees of separation”. Steven Strogatz har skrevet nogle klummer i New York Times om matematik. De er meget velskrevne. Egenskaber ved small world grafer: Afstanden melem tilfældige knuder er kort – som i et netværk, hvor kanterne er indsat tilfældigt. (Med samme totale antal kanter. Afstanden er naturligvis kortes, hvis alle er forbundet med alle.) Fjernes en tilfældig knude vil gennemsnitsafstanden mellem andre knuder sandsynligvis ikke stige voldsomt. (Gør man det i en graf, hvor kanterne er indsat tilfældigt, er der stor sandsynlighed for, at andre skal gå en omvej). Til gengæld er small worlds sårbare overfor bevidste angreb: Man kan ved at fjerne få udvalgte knuder skabe mange problemer for de andre.
Matematikken bag er grafteori kombineret med bl.a. sandsynlighedsteori.
Otto snakkede om “adjacency matricer”. Her er et billede fra Wikipedia. Der er et 1-tal i femte tal i øverste række, fordi der er en kant fra knude 1 til knude 5. I række 6 er der kun et 1-tal, nemlig i fjerde søjle. Det skyldes, at knude nummer 6 kun er forbundet til knude 4. Ganger man matricen med sig selv, kan man se, hvilke knuder, der kan forbindes i to skridt. Etc.
Lige lidt mere om punkt match.
På http://greatpanic.com/pntmatch.html er beskrivelse af, Denton/Beveridge algoritem. To billeder gennesøges først for hjørnepunkter med en hjørnepunktsalgoritme. Matching sker iteativt: Start med en lille delmængde af billede 1 og find et match til dem. Nu forsøger vi at udvide med endnu en lille delmængde etc. Tilder ikke er flere muligheder. Hvis alle er matchet, er vi glade. Ellers starter vi forfra med en ny delmængde (en “seeding”, et såsæd.) udvider etc.
Billedet fra http://greatpanic.com/pntmatch.html viser, hvordan punkter, der matches iterativt.
Mere kendt er RANSAC, (RANdom SAmple and Consensus) som
1) Vælger (tilfældigt /random) en lille mængde punkter og matchende punkter
2) Udfra dette match beskriver en afbildning (rotation og parallelforskydning for eksempel)
3) Regner på, hvor godt resten af punkterne matches ved denne afbildning.
Der var matematik i, da Carlie gennemsøgte overvågningsvideooptagelser, for at finde morderen. Jeg hørte det som “Point pattern matching” og line detection/edge detection. Der var “gait analysis”, hvor man identificerer folk på måden, de går på. Så var der separation af skygger på deb grumme video.
Point pattern matching
Jeg har fundet en “tutorial” om det overordnede problem: Man har nogle punkter, et punktmønster, givet ved deres koordinater (x1,…,xd), som kan repræsentere sted, farve, hastighed,…. Lad os sige, vi har 100 af dem på èt billede. Og vi har 100 punkter, et andet punktmønster, på et andet billede – på en anden overvågningsvideoer for eksempel. Er de så “det samme”, altså omrids af samme person, samme bil,…
Det kan de godt være, uden at se ens ud. Man kan se dem fra en anden vinkel, der kan være ændret lys, …
Det beskrives matematisk ved nogle tilladte afbildninger (funktioner) tænk f.eks. på rotationer. Spørgsmålet lyder nu: Findes der en tilladt afbildning, der bringer det ene punktmønster over i det andet.
Og ydermere: Findes der en algoritme, der afgør det? Og afgør det hurtigt.
Lad os holde os til translationer (parallelforskydning) og rotationer. Og at vores punkter har to koordinater, i.e., det foregår i planen. Vi har to punktmønster, A og B. Opgaven er at flytte A saa tæt på B som muligt, og så dernæst afgøre, om det er tæt nok til, at vi vil sige A og B er billeder af det samme.
Eksempel: Hvis der er tre punkter p,q,r i A og tre punkter s,t,u i B, så gælder det om at skubbe trekanten givet ved a,b,c over i trekanten s,t,u. Og det er ikke klart, om a skal ligge tættest på s eller t eller u.
Det er et enormt område, der er anvendelser mange steder, og algoritmerne tilpasses det område, de skal bruges på. I astronomi kunne man måske interessere sig for at finde stjernekonstellationer. De består af et lille antal punkter, så en optimal algoritme til det kan være helt anderledes end den, der bruges til store punktmængder.
Med et lille antal punkter kan man sommetider bruge en “brute force” algoritme, som gennemsøger alle flytninger af A og ser, hvilken der giver kortest afstand til B. Afstand til B findes ved (d(p,s)+d(q,t)+d(r,u)) hvor d(p,q) er afstanden fra det flyttede punkt p til q
og så d(p,t)+d(q,u)+d(r,s)
og endelig d(p,u)+d(q,s)+d(r,t)
Den mindste af disse er afstanden – vi har så taget hensyn til, at vi ikke ved, hvilke hjørner i A, der skal svare til hvilke i B. Kender man ikke “omløbsretningen ” for A og B er der flere muligheder, man skal undersøge.
Skyggeseparation. Her er en temmelig langhåret artikel om, hvordan man finder det, der er gemt i skyggen på et billede. Der er fysik i: Lys polariserer, og det skal udnyttes. I denne artikel kan de ikke behandle gamle billeder. Man optager billeder med information om polarisering (ved at optage på flere bølgelængder, tror jeg nok), og så kan man bagefter finde det, der er i skyggerne.
Andre tilgange (shadow segmentation hedder det, hvis I vil søge) går ud på, at spketret – fordeleingen af rød, grøn, blå i skyggen er anderledes end i noget, der er belyst. På den måde kan man automatisk opdage, når noget er i skyggen, og forøge intensiteten der – til Videokonferencer for eksempel.
Man har også mere geometriske metoder, hvor man bruger, at skyggers facon er givet ved andre objekter. Og så leder man efter figurer, der kunne være fremkommet som skygger.
Larry er tilbage! Jeg har savnet ham. Matematikken var noget crowd flux, altså dynamikken i, hvordan flokke bevæger sig. Der vr en “retrograde analysis” af, hvor forbryderne skulle sidde for at sidde optimalt. Ansigtsgenkendelsesalgoritmer blev også brugt. Crowd dynamics – mylderdynamik
Det har vi haft på bloggen tidligere, men jeg vil opdatere jer lidt. Store flokke af mennesker kan mase hinanden ihjel, som vi har set det flere gange. Keith Still har en lang liste. Keith Still er matematiker og underviser i, hvordan man undgår den slag ulykker ved f.eks. at lave udgange de rigtige steder, at sætte skilte, at sætte barrierer, så folk ikke maser i midten og skaber propper.
Der er flere væsensforskellige måder at betragte den type problemer på: Man kan se på hver enkelt aktør i sammenhæng med de andre og simulere det samlede forløb – hver aktør reagerer på de andres bevægelser. Det er i branchen kompleske systemer, som er en blanding af fysik, datalogi og matematik.
Man kan anlægge en “flow” betragtning – man betragter flokken på samme måde som en væske og ser på hvor mange der er på vej gennem en dør på et givet tidspunkt, og ikke så meget hvem det er. En lidt anden vinkel er den, vi kender fra termodynamik/statistisk mekanik, hvor rigtig mange molekyler betragtes fra en statistisk synsvinkel.
I USA er Mathematics Awareness Month 2011 netop om komplekse systemer. Der er mange links, som I kan surfe rundt i.
Det, Charlie og co. bruger her, er “agent based simulation” – så vidt jeg kan se. Det er der masser af artikler om på nettet. For større områder kombinerer man med GIS (Geografiske Informationssystemer), atlså kort og information om transport etc. For bygninger skal man bruge en plan over bygningen inklusive møbler, hvad vej dørene åbner, belysning, skiltning,… Jo mere info, jo bedre model, men som altid må det afbalanceres med, hvor godt et program og hvor stor en computer, man har til rådighed. Hver enkelt agent har sit eget reaktionsmønster (det kan være det samme for alle, men behøver det ikke.) Og så kører man en simulation af, hvad de gør.
(Tilføjet 2023 – gamle links var døde…)Det er der mange firmaer, der laver software til. For eksempel UCrowds men der er mange andre. Jeg har ikke fundet gratis software, men der er videoer som denne på YouTube
Amita arbejder igen! Og så til matematikken. Der var flere emner oppe: Genetik – delvis match af DNA spor bruger statistiske metoder. Fuzzy search. Scale gradient projection. Geografisk profilering. Neurale netværk til billedrekonstruktion. GPS.
Scaled Gradient projection
Billederne fra overvågningskameraerne er ikke gode (måske forsøgt slettet), og Amita bruger “scaled gradient projection” metoder til at genfinde et godt billede. Metoden forklares af Charlie i en analogi med løsning af kryds og tværs, hvor nogle bogstavsammensætninger er umulige.
Et billede kan beskrives som en (lang) vektor x=(x1,x2,….,xN) hvor hver koordinat er farven af en pixel.
Det billede er ny blevet forvansket. Man har måske støj, en vektor n=(n1,….,nN), og en “blurring” afbildning H(x), som antages at være lineær – man ganger med en matrix (hvis læseren er utryg ved matricer, så tænk bare på H(x1,x2)=(ax1+bx2,cx1+dx2))
Det billede, vi ser, er
y=Hx+n
Nu gælder det om at finde x. Vi kender ikke H og n præcist; vi har måske visse ideer om H udfra eksempelvis tekniske oplysninger om kameraet eller om lagringen af billedet. Vi ved til gengæld, x er et billede – det er ikke et tilfældigt mylder af pixelfarver. Der er en mængde M af mulige billeder, så x tilhører M.
Opgaven er så: Find det x fra M, som mest sandsynligt giver anledning til det forvrængede billede, y. Det er maximum likelihood metode.
Det problem, man nu står med, er et optimeringsproblem med en begrænset mængde mulige løsninger, M. Og en funktion, der beskriver noget om, hvor god hver løsning er – likelihood funktionene, men det kunne også være et andet mål for, hvor god løsningen er. Gradientagtige metoder til optimering:
Vælg et x, udregn f(x), og de afledte af f i x. Gå nu et (lille) stykke i den retning grad(f)(x), hvor f vokser mest (langs gradienten). Gør det igen i det punkt, man nåede til. Man går rundt på grafen for f over M. Går i den retning, hor f vokser mest og håber at ende på den højeste top. Man vælger sædvanligvis flere udgangspunkter og ser, hvor man ender fra hver af dem. Så undgår man, at man rammer en lille bule, som ikke er et maksimum.
Biledet (fra Wikipedia viser niveaukurver for en funktion, som svinger meget, og hvor man derfor får zig-zag opførsel på vej mod toppen.
Den metode, Amita bruger, indebærer et smart valg af skridtlængden. Og desuden, at man ikke nødvendigvis følger retningen grad(f)(x), men måske lidt skævt. Og så er der, så vidt jeg kan se, en projektion, der sender en tilbage i M, hvis man er røget udenfor. Her er slides fra en præsentation af scaled gradient projection.
Delvis match af DNA
Koblingen mellem DNA og ydre karakteristika – fra genotype til fænotype – kan være meget indviklet, men der er egenskaber, som er forholdsvis simpelt kodet. I dette afsnit taler de om “hazel” øjenfarve og om en høj brunette, og det hentyder formentlig til arbejde på Stanford. Formidlingssitet “Understanding Genetics” har et indlæg om netop den øjenfarve. Hæmofili kan skyldes en defekt på X-kromosomet. Det er recessivt, så kvinder får det kun, hvis begge deres X-kromosomer har defekten, hvorimod mænd, som jo kun har et X-kromosom, får sygdommen, hvis dette X-kromosom har defekten. Det ser ud til i serien, at den ene søster er bærer, mens den anden har to defekte X-kromosomer, og altså er syg.
Amita søger efter delvise match, eller muligvis bare efter hæmofilibærere, i DNA databasen. Jeg ved ikke, om hæmofili faktisk kan ses af DNA-registeret. Umiddelbart skulle man ikke tro det, for det er en pointe, at den del af DNA, man registrerer, er “junk” dna, som altså ikke koder for noget, man umiddelbart kan se. Hvis nu man faktisk brugte “genet for brunt hår” (hvis der er sådan et), så ville en mistænkt, der var kaldt ind, fordi et vidne havde set en brunette jo ikke være yderligere mistænkelig udfra DNA – for vi vidste, det var en brunette. Det drejer sig om uafhængighed. Tilføjet 30/4: At det er junk DNA, der registreres, er en konsekvens af, at man registrerer dele af DNA, som har stor variation i befolkningen – Ellers er der jo ikke nogen information i, hvordan mit DNA ser ud på det sted. Og de dele af DNA, der koder for noget, har ikke så stor variation. (Tak, Svante. Så blev jeg igen klogere)
Delvis match af DNA med henblik på at finde familiemedlemmer til dem, der allerede er i databasen er kontroversielt – linket er til New York Times. Problemet er, at man finder potentielle mistænkte ved en slags antagelse om, at familiemedlemmer til forbrydere er mere sandsynlige gerningsmænd/kvinder end den generelle befolkning. Man finder et delvist match, henter hele familien ind og finder så en, der mathcer fuldstændig. Hvis man så dømmer den person udelukkende ud fra DNA match (og manglende alibi), halter argumentet “der er sandsynligvis kun xxx personer, som matcher, og det er meget få ud af hele befolkningen, så derfor…” – for hvad med de xxx-1 andre? Måske har de heller ikke noget alibi. Men de blve ikke fundet, fordi deres familie ikke var i databasen og gav et delvist match.
Igen var Amita åbenbart for optaget af bryllupsplanerne til at lave noget matematik – skal man være det i en amerikansk serie? Nå. Matematik var der jo alligevel. Jeg så noget med reverse trajectory problem (hvor kom kuglen fra). Og noget om 4 dimensionale data.
Projektiler Det er let at regne på projektilbaner, hvis ikke der er luftmodstand. Her kan man se, hvordan banen afhænger af vinkel, hastighed og højde, man kaster/skyder fra: Kasteparabler i JAVA Men med luftmodstand bliver det sværere – luftmodstandens størrelse er ikke konstant, men afhænger af hastigheden, og det gør ligningerne indviklede. Det drejer sig om differentialligninger – men det får I ikke mere om.
4dimensionale data Charlie ville kortlægge containerne i sted og tid, så han kunne se uregelmæssigheder i mønsteret. I følge statistik fra Los Angeles’ containerhavn, kom der 600.000 TEU (Twenty Foot Equivalent Units) containere gennem havnen i marts 2011, så det er et enormt område at holde øje med, og man kan sagtens forestille sig, det er muligt at gemme noget der. Gode visuelle repræsentationer af data er nyttige, fordi vores hjerne er god til at se strukturer i billeder. Data, som er både rumlig og tidslig, kan f.eks. vises som en slags film. Eller man kan vise variationen af et 2d lag, Der er mange muligheder.
Her er et tredimensionalt billede af en 4-dimensional kube, som roterer. Billedet er en projektion – man kan forestille sig, hvordan den 2-dimensionale skygge af en en 3d kasse vil se ud. -Og så er der en dimension mere. En 4-dimensional kasse/kube er de punkter (x,y,z,w), som opfylder, at alle koordinater ligger mellem 0 og 1. Videoen viser kanterne – eksempelvis (0,0,0,w) hvor w løber mellem 0 og 1. De andre er (1,0,0,w) (0,1,0,w) (0,0,1,w) (1,1,0,w) (1,0,1,w) (0,1,1,w) (1,1,1,w) Og tilsvarende, hvor x, y eller z løber – der bliver 32 kanter. Skærer man den over i f.eks. w=0 og ser på snitfladen, får man en 3-dimensional kube. Det får man for hvert w melem 0 og 1. Så man kan tænke på den 4-dimensionale kasse, som en lille film med 3d kasser, hvor w er tidskoordinaten. Så er der ingen kasser, før w=0, og kassen er der i tidsrummet mellem 0 og 1. Derefter en den væk igen. En 4d kugleflade er punkter (x,y,z,w), som opfylder x^2+y^2+z^2+w^2=1. Hvis vi opfatter det som en film med w som tidskoordinat, så er der ingenting, før w=-1. I w=-1 er det et punkt. For w mellem -1 og 1 er der en kugleflade med radius kvadratroden af (1-w^2). Den bliver altså større mellem w=-1 og w=0, hvor den har radius 1. Så skrumper den og bliver til sidst til et punkt i w=1.
Visuelle repræsentationer af data er både forskning og forretning. Her er et 3d billlede af et stort proteinmolekyle. Det kunne man naturligvis have bygget selv, men det er meget lettere at lave det i computeren. Og det giver helt nye muligheder i mange videnskabelige discipliner. Billedet er fra Wikipedia. Repræsentation af statistiske data er også et væsentligt område. Man kan både informere og misinformere ved valg af grafisk repræsentation.
Der var problemer med tilfældighederne. De pseudotilfældige tal, som oplyste sammenhængen mellem serienumrene på skrabelodder og gevinsten, var ikke gode nok, så man kunne gætte systemet. Der var også noget om fractional diffusion equations. Og så morede jeg mig over lottoekspertens bemærkning: “I love the smell of probability in the morning.”
Pseudotilfældige tal. Jeg har skrevet om pseudotilfældige tal tidligere, og det kan jeg da anbefale, at man læser igen 🙂 Der står f.eks. noget om Mersenne Twister metoden og Blum Blum Shub, så det får I ikke her. Man har brug for tilfældige tal i mange sammenhænge, og det er forbavsende vanskeligt at lave et system, der leverer sådanne tal. Når man tænker over det, er det måske ikke så mærkeligt: Har man lavet et system, er det jo ikke tilfældige tal, der kommer ud – de er systematiske i en eller anden forstand. Man kan lave egentlig tilfældighed ved at bruge kvantemekanik – lade tallene være en slags funktion af henfald af et radioaktivt stof som hos HotBits. Eller man kan bruge atmosfærisk støj, som de gør på random.org.. Den slags frembringere kaldes TRNG (True Random Number Generator.) Man kan få en god filosofisk diskussion ud af, om det er rigtig tilfældigt at bruge atmosfærisk støj, eller det bare er deterministisk kaos. Men det er meget besværligt at lave mange rigtigt tilfældige tal, så hvis man skal bruge mange, og det ikke er helt så vigtigt med sikkerheden, laver man pseudotilfældige tal, som er helt systematisk frembragt, men på en måde, så det er meget svært at gætte systemet, og så alle tal har lige stor sandsynlighed for at fremkomme.
Her er et mønster frembragt af random,org TRNG (man genererer en meget lang stribe 0’er og 1’er og maler pixels hhv. sorte og hvide alt efter om de svarer til 0 eller 1:
Og her er et, der er frembragt af PHP rand() på Microsoft Windows Begge er lavet af Bo Allen, som sammenligner frembringere af tilfældige tal. Funktionen PHP rand() giver meget bedre resultater på Linux, siger Bo Allen. Der er nok ikke nogen, der er i tvivl om, at det nederste mønster har struktur. Men det er ikke altid så nemt at gennemskue. Det er da også en fejl i kombinationene med Windows,, og der er ikke nogen, der vil påstå, at det er et godt eksempel på PRNG
I 2007 havde Danske Spil brugt en fejlagtig frembringer af pseudotilfældige tal, en PRNG, til lynlottorækker købt over nettet. Fejlen betød, at talene 1-9 havde for lav sandsynlighed for at være med på de rækker, man købte. Er det så en ulempe for spillerne? Sandsynligheden for at den række, man har købt, bliver udtrukket, er uafhængig af, hvad det er for en række, og om den er fremkommet tilfældigt eller det er familiens fødselsdage, så umiddelbart er svaret nej. Men hvad med størrelsen af gevinsten? Man deler jo gevinsten med de andre, der har spillet på den række. Hvis en række uden tallene 1-9 bliver udtrukket, er der jo flere, der har spillet på den, end hvis alle tal var jævnt repræsenteret blandt de spillede rækker, og så er gevinsten lavere. Og den er højere, hvis gevinstrækken indeholder 1-9, og den har man så mndre chance for at have som internetlynlottospiller. Til gengæld er der mange, der spiller på fødselsdage, hvor 1-9 er overrepræsenteret (som fødselsmåneder.) Danske Spil fik Henrik Spliid fra DTU til at dels regne på problemet og dels lave en simulation, og han konkluderede, at lynlottospillerne ikke havde haft et tab. Netop fordi der var fordele og ulemper, der opvejede hinanden.
Havde man derimod haft problemer med tilfældigheden i udtrækning af vinderne, havde det været en helt anden sag.
Kriterier for pseudotilfældighed. Hvornår er en frembringer af pseudotilfældige tal god nok? Det tyske Bundesamt für Sicherheit in der Informationstechnik, BSI, har opstillet nogle kriterier eksempelvis (her er K1 de laveste krav, og en K2 skal opfylde K1 kriterierne etc.:
K1: Der skal være en stor sandsynlighed for, at vi fr forskellige følger af tal ud af en PRNG. En følge af tal beskrives her som en vektor. Mere præcist: Sandsynligheden for, at vektorer frembragt af vores PRNG, (r1,…,rc)(r{c+1},…,r2c),…,(r{(M-1)c+1},…,rMc) er parvis forskellige er mindst 1-e, hvor e er et lille tal. Hvis e < 2^(-16) og M^2/(c^2 e) >2^(52) er det styrken af vores PRNG høj.
K2 Tallene skal opfylde de samme statistiske kriterier som sande tilfældige tal. Mere præcist:
Frembring 20000 binære tal b1,…,b20000.
Test 1: Læg dem sammen (ikke binært, men rigtig addition). Så skal summen ligge mellem 9654 og 10346. Det vil rigtige tilfældige tal bestå med sandsynlighed 1-10^(-6)
Test 3: Man ser på hvor lange følger af 0’er, der optræder i b1,…, b20000, det kaldes “run length”. Antallet af følger med kun et 0 (altså …101…) skal ligge mellem 2267 og 2733, antallet af følge med to nuller (…1001…) blandt de 20000 skal ligge mellem 1079 og 1421 etc. som man ser på listen her: Den sidste er antallet af følger med 6 eller flere. De samme krav skal gælde for 1-tallerne.
1 2267-2733
2 1079-1421
3 502-748
4 233-402
5 90-223
6 90-233
Test 4: Der må ikke være nogen “run length” på mere end 34.
Der er andre tests, men dem kan I finde i artiklen fra BSI.